python と 深層学習の勉強のつもりで Chainer のソースコードを追ってみました。順伝播と誤差逆伝播をどのように実現しているのか書いてみます。
(ソースのバージョンは 1.7.0 です。2016 年当時のもので、情報として若干古くなっています)
Variable と Function
おおまかに言うと、Chainer は
- データは Variable に保持
- 計算は Function (の具象クラス)で実行
します。
ここでデータと呼んでいるのは、学習データのほか、ユニット間の重み、そしてバイアス等のパラメータも指しています。
Function にはさまざまな具象クラスがあり、それぞれ固有の計算ロジックを実装していますが、共通ルールとして、forward メソッドで順伝播、backward メソッドで逆伝播を処理しています。
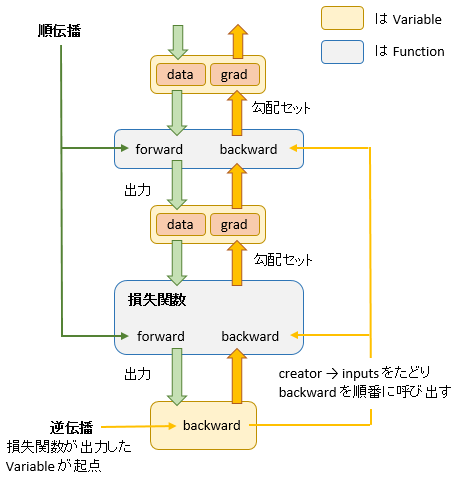
そして下図のように、Function は Variable を入力として受け取り、Variable を出力します。
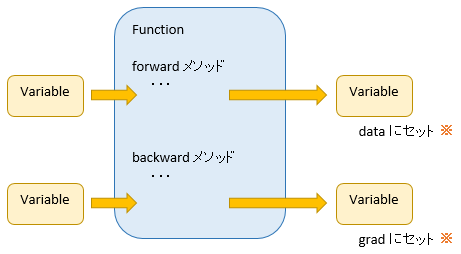
※ Variable には data と grad という 2 つの領域があり、forward の処理結果は data に、backward の処理結果は grad にセットされます。

data と grad
Variable の data は 配列です。次元数は扱うデータによって変わりますが、学習データは、この data 配列にのってレイヤー間を運ばれていきます。
ユニット間の重み、バイアスも data に保持されます。
- 重みを保持する場合、data の各要素は各ユニット間の重みを表します。
- バイアスを保持する場合、data の各要素はユニットのバイアスを表します。
grad も配列で、サイズは data と同じです。誤差逆伝播の過程で勾配やデルタ(後述)がセットされます。
順伝播
レイヤーの出力は次レイヤーの入力
順伝播では、各レイヤーごとの出力が、次のレイヤーの入力になります。
プログラムに置きかえていうと、各レイヤーごとに Function が(1 つ以上)あり、Function の forward メソッドが data に処理をほどこし、その結果が次レイヤーの Function へ次々に引き渡されていきます。
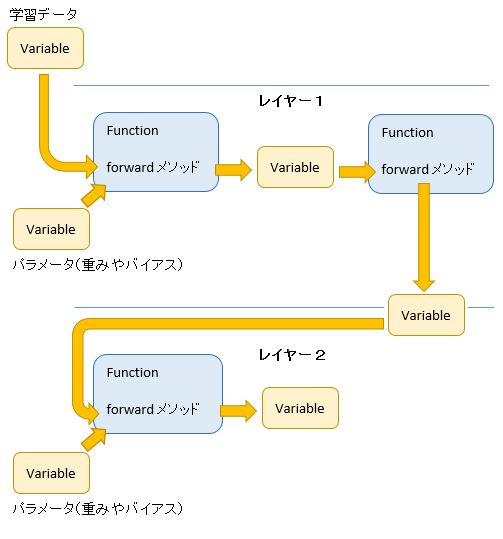
全結合の場合
全結合の場合、各レイヤーの順伝播の処理は
- ① 入力値に重みやバイアスをかけあわせ
- ② さらに活性化関数を適用
して出力値を算出します。
①には LinearFunction を、②の活性化関数にはいろいろ選択肢がありますが、例としてReLU を適用すると下図のような構成になります。
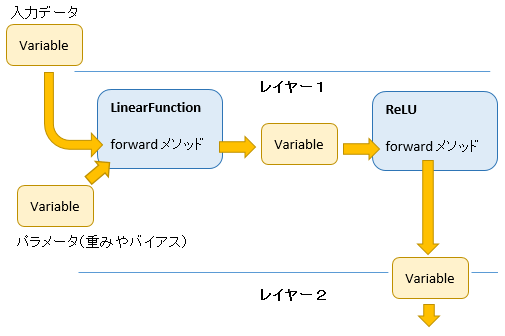
LinearFunction の foward
せっかくなので LinearFunction の foward 処理を見てみます。入力データに重みとバイアスをかけあわせているのが判ると思います。

逆伝播
逆伝播の処理は、順伝播で生成したインスタンスを逆からたどるように行います。
逆からたどる? どうやって?
順伝播の際にインスタンス同士が紐づけされており、inputs、outputs、creator として互いに参照できるようになっています。
その紐づけ情報を利用し、creator → inputs と次々にたどって backward メソッドを呼び出していきます。
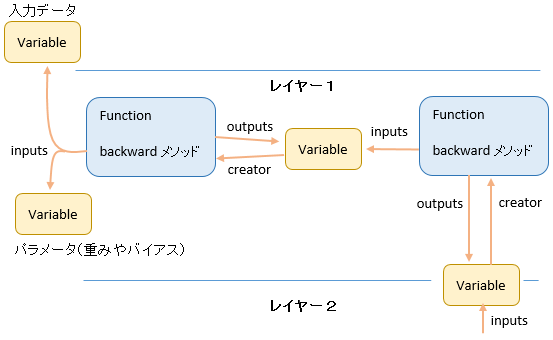
紐づけ(inputs、outputs、creator)を行う箇所をソースで確認してみます。

紐づけをたどっていくのは Variable の backward メソッドです。
(長いので引用しません)
backward メソッドの処理
Function の backward メソッドで下記を計算します。
- ① 重み W の勾配
- ② バイアスの勾配
- ③ 下位層へ引き渡す値
最後の ③ は青本 「深層学習 (機械学習プロフェッショナルシリーズ)」 の式(4.11)で デルタ \(\delta \) と呼んでいるものに相当します。
①②③ の計算結果は inputs 先の Variable(の grad) にそれぞれセットされます。
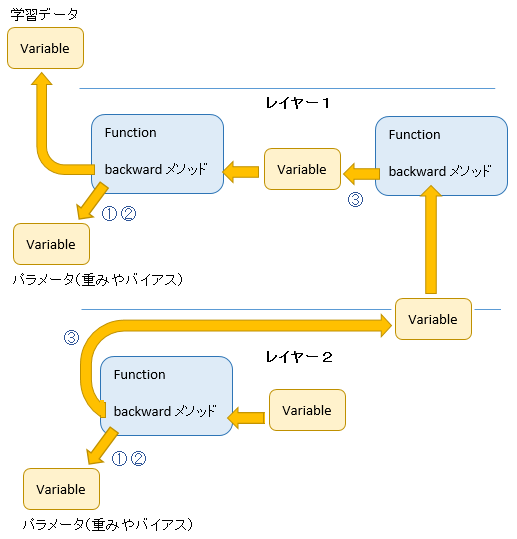
図を見るとわかると思いますが、上位層 (図では下側) のデルタが下位層に次々渡されています。(③ の流れ)
誤差逆伝播では、上位層のデルタを引継ぎながら勾配を計算しますが、図のような仕組みがあることでそれが実現されています。
LinearFunction の backward
backward メソッドの一例ですが、LinearFunction は次のようになっています。

backward の起点は Variable
出力層で損失関数を適用するのが順伝播のゴールになりますが、そこは逆伝播のスタート位置ともいえます。ソースを見ると
というコーディングをいくつか目にするのですが、loss は損失関数の出力した Variable で、その Variable に定義された backward を呼ぶことで逆伝播がスタートします。
パラメータ更新は Optimizer
backward で重みやバイアスの勾配が計算され Variable にセットされますが、その時点では grad 上に値がセットされただけです。学習を完了させるためには、この値を data に反映させる必要があります。なぜなら、順伝播の処理が参照するのは data だからです。
この grad ⇒ data を実行するのは Optimizer の update メソッドです。
Optimizer はいろいろ
重みやバイアスの更新には単純なものから複雑なものまでいろいろなロジックがありますが、ロジックごとに Optimizer の具象クラスが用意されています。一番簡単そうな SGD クラスのソースはこうなっています。

引数 param として、勾配のセットされた Variable が渡されます。
tiffblue says:
参考になりました!
管理人 says:
tiffblueさん
コメント有難うございます。
M says:
すごいですね。大変参考になりました。よくわからず困ってました。ありがとうございます。
管理人 says:
Mさん、こんにちわ
コメント有難うございます。
古いソースではありますが、お役に立てたなら嬉しいです。
OKEMARU says:
自動微分とバックプロパゲーションの関係が理解できず悩んでいました。自動微分さえあれば、バックプロパゲーションの偏微分の式は不要なのでは誤解していましたが、こちらの解説で、自動微分はバックプロパゲーションの計算を高速にするためのテクニックということが、腑に落ちました。
ありがとうございました。。
管理人 says:
OKEMARUさん
コメント有難うございます。
匿名 says:
やっと理解できたような気がします。
ありがとうございました。
K says:
やっと理解できたような気がします。
ありがとうございました。