主成分分析なんかでよく出てくる共分散行列。
- numpy.cov
- pandas なら DataFrame の cov()
で計算してくれます。
ちなみに、共分散行列には2種類あります。
- 標本共分散行列 : \(\large\frac{1}{n}\sum_{i=1}^n (\vec{x}_i-\vec{m})(\vec{x}_i-\vec{m})^T\)
- 不偏共分散行列 : \(\large\frac{1}{n-1}\sum_{i=1}^n (\vec{x}_i-\vec{m})(\vec{x}_i-\vec{m})^T\)
(n はデータ数、\(\vec{m}\) は平均値のベクトル)
n で割るか、n-1 で割るかの違いです。
- 目次 -
スポンサーリンク
numpy
標本分散、不偏分散のどちらも計算できます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
import numpy as np a = np.array([[1,2],[2,4],[3,6]]) #--------------------------- # array([[1, 2], # [2, 4], # [3, 6]]) #--------------------------- # 標本分散(bias=1) np.cov(a, rowvar=0, bias=1) #------------------------------------- # array([[ 0.66666667, 1.33333333], # [ 1.33333333, 2.66666667]]) #------------------------------------- # 不偏分散(bias=0) np.cov(a, rowvar=0, bias=0) #--------------------------- # array([[ 1., 2.], # [ 2., 4.]]) #--------------------------- |
デフォルトは不偏分散(bias=0)です。
rowvar
上の例はデータが縦方向に並んでいる場合の計算です。
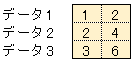
下図のように、データが横方向に並んでいる場合は rowvar=1 を指定します。
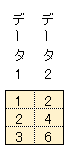
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
np.cov(a, rowvar=1, bias=1) #-------------------------------- # array([[ 0.25, 0.5 , 0.75], # [ 0.5 , 1. , 1.5 ], # [ 0.75, 1.5 , 2.25]]) #-------------------------------- np.cov(a, rowvar=1, bias=0) #-------------------------------- # array([[ 0.5, 1. , 1.5], # [ 1. , 2. , 3. ], # [ 1.5, 3. , 4.5]]) #-------------------------------- |
pandas の DataFrame
不偏分散だけのようです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
from pandas import DataFrame df = DataFrame([[1,2],[2,4],[3,6]]) #----------- # 0 1 # 0 1 2 # 1 2 4 # 2 3 6 #----------- df.cov() #----------- # 0 1 # 0 1 2 # 1 2 4 #----------- |