gensim の Phrases を使えば、文書に頻出するフレーズ(単語の組合せ)を簡単に探せることを こちら で見ました。この Phrases を使って、辞書に未登録の複合語を探してみようと思います。
たとえば “プログラム言語” とか “拡散希望”、 “女子会” といった単語を拾いだしてみたいと思います。
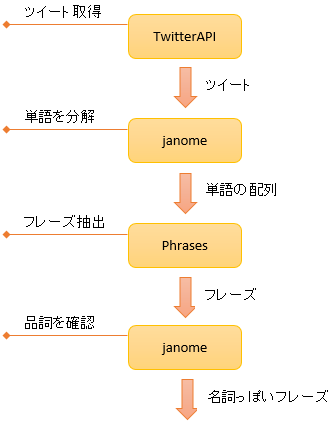
元ネタの文書として twitter のツイートを使うことにします。
使用ツール
TwitterAPI
ツイートを大量に取得するため TwitterAPI を利用します。
こちら で作った python コードを利用します。
Janome
単語の分割や品詞の判定には janome を使います。
バージョンは 0.2.8 以降。
Janome について
Phrases
ツイートから頻出フレーズを抜き出すために Phrases を使用します。
Phrases について
名詞だけ
フレーズのうち、名詞とみなせそうなものだけ拾いだすことにします。
文法的な正しさはちょっと横に置いておいて、次のルールを設けます。
名詞 + 名詞のフレーズは多分 名詞
名詞 + 名詞 はきっと名詞だろうという安易な想定ですが、たとえば、次のようなフレーズを拾えるようにします。
ただし、名詞とはいえ、1号店、2号店のように数字が混ざるものははずします。
また、固有名詞も除外します。
ひらがなだけのフレーズもはずします。”げげ” とか “らら” を除外するためです。
動詞も一部 OK
飲み放題 という単語も拾いたいのですが、”飲み” は動詞です。
そこで、動詞は、連用形なら OK とします。
(”飲み” は “飲む” の連用形)
パラメータ
以下の 2 項目をパラメータ指定できるようにします。
- キーワード
ツイートの検索キーワード - ツイート件数
ツイートを取得する件数
ユーザー定義辞書も指定できるようにします。
出力形式
CSV形式
MeCab 辞書フォーマットの CSV 形式で出力します。ファイルに落とせば janome のユーザー辞書として使えます。もちろん MeCab の辞書更新にも使えます。
品詞やコスト等は固定
品詞は名詞(一般)を固定でセットします。
左文脈ID、右文脈ID、コストも固定値をセットします。
読み、発音も * を固定でセットします。
プログラム
ソース
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 |
# -*- coding: utf-8 -*- from janome.tokenizer import Tokenizer import codecs from gensim.models import Phrases # http://ailaby.com/twitter_api/#id6_1 のソースを # tweetsGetter.py で保存 from tweetsGetter import TweetsGetter tokenizer = None def isNoun(word): ''' 名詞とみなせるか判定 Args: word : _で区切られたフレーズ あああ_いいい_ううう ''' if word.find(u' ') >= 0 or word.find(u' ') >= 0: return False if word.find(u'\n') >= 0 or word.find(u'\r') >= 0: return False tokens = tokenizer.tokenize(word) for num, token in enumerate(tokens): surFace = token.surface part0 = token.part_of_speech.split(',')[0] part1 = token.part_of_speech.split(',')[1] baseForm = token.base_form inflForm = token.infl_form if surFace == '_': continue # 名詞の baseForm != '*' ⇒ '#' ,'^', etc をはじくため if (part0 == u'名詞' and part1 != u'数' and part1 != u'固有名詞' and baseForm != '*') or \ (part0 == u'動詞' and inflForm == u'連用形' and num != (len(tokens)-1)): continue return False # ひらがなだけの場合は除外 for ch in word: if (ch < u'ぁ' or ch > u'ん') and ch != '_': return True return False def findNewWords(keyword, tweetsCount = 500, udic = None, udic_enc = 'utf8'): ''' 辞書にない新語を探す ''' global tokenizer if udic: tokenizer = Tokenizer(udic=udic, udic_enc=udic_enc) else: tokenizer = Tokenizer() #------------------------ # ツイートを取得 #------------------------ tweets = TweetsGetter.bySearch(keyword).collect(total=tweetsCount, onlyText=True) #--------------------------------- # 単語を分割 # # corpus = # [ # ['1', '番目', 'の', 'ツイート'], # ['2', '番目', 'の', 'ツイート'], # ['3', '番目', 'の', 'ツイート'], # ・・・ # ] #--------------------------------- corpus = [] for tweet in tweets: # Phrases の区切り文字 '_' を空白に置き換えてから単語を分割 tokens = tokenizer.tokenize(tweet.replace('_', ' ')) corpus.append([token.surface for token in tokens]) #------------------------ # Phrases で変換 #------------------------ gramCnt = 5 # 2:bigram 3:trigram ・・・ for i in range(gramCnt-1): phrases = Phrases(corpus) transformed = phrases[corpus] corpus = transformed #------------------------ # 名詞とみなせそうな単語を探す #------------------------ phraseWords = [] for sentence in transformed: for word in sentence: if word.find('_') >= 0 and word not in phraseWords: phraseWords.append(word) if isNoun(word): yield word.replace('_', '') if __name__ == '__main__': infile = None #'userdict_i.csv' outfile = None #'userdict_o.csv' if outfile: fo = codecs.open(outfile, 'w', 'utf8') for newWord in findNewWords(u'グルメ', tweetsCount=5000, udic=infile): line = u'%s,-1,-1,3000,名詞,一般,*,*,*,*,%s,*,*' % (newWord, newWord) print line if outfile: fo.write(line + '\n') if outfile: fo.close() |
パラメータ
キーワード:グルメ
ツイート件数:5000 件
となっています。
結果
キーワード:グルメ
(以下は一部のハードコピーです。こちらに、全テキスト)

キーワード:人工知能
キーワードを変えて試します。”人工知能”
(以下は一部のハードコピーです。こちらに、全テキスト)
