selenium を使って yahooニュースのコメントをクロールし、スクレイピングしてみます。ブラウザは PhantomJS を使います。プログラムは python です。
- 目次 -
スポンサーリンク
インストール
selenium と PhantomJS のインストールは非常に簡単です。
selenium
コマンドプロンプトで以下を入力します。
|
1 |
pip install selenium |
PhantomJS
こちら から ZIP をダウンロードし、適当な場所に解凍します。(解凍先のパスをプログラムで指定します)
起点はコメント一覧
クロールの起点はコメント一覧のページにします。ニュース記事の下部で次のリンクをクリックして遷移するページです。
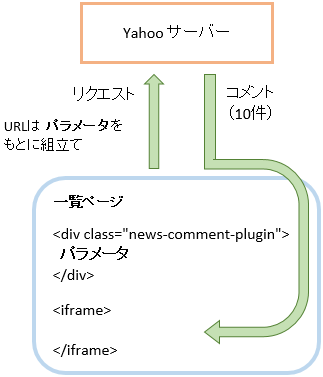
コメント取得の仕組み
一覧ページのコメントは iframe で表示されています。JavaScript でコメントを取得しているようですが、取得用の URL は動的に組み立てているようです。組み立てに使うパラメータは
<div class=”news-comment-plugin”>
の属性としてセットされています。このパラメータを組み立てると、コメント取得の URL ができあがります。下図のイメージです。
返信コメント
各コメントに対する返信コメントは 最初は 3件しか表示されません。4件以上の返信コメントがある場合は 以前のコメントを表示 リンクを click します。click すると、3件づつコメントが追加表示されます。
スクレイピング・プログラム
上記をふまえ、作成するプログラムは次のようにします。
一覧の各ページに対して
- URL を組み立て
- その URL でページを取得(ページは 10件のコメントを含んでいる)
- ページ内の返信コメントを全て表示
- その結果生成されるページからコメントを取りだす
これを、最終ページまで繰り返します。
以下、ソースです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 |
from selenium import webdriver from selenium.webdriver.common.keys import Keys import time class CommentCrawler(object): def __init__(self): self.driver = webdriver.PhantomJS(executable_path='C:/phantomjs-2.1.1-windows/bin/phantomjs.exe') def page(self, url): self.driver.get(url) self.url = url self.title = self.driver.title def crawl(self): if not hasattr(self, 'url'): raise Exception('call page() before crawl()') pluginOp = self.driver.find_element_by_css_selector('div.news-comment-plugin') data_sort = pluginOp.get_attribute('data-sort') data_order = pluginOp.get_attribute('data-order') data_keys = pluginOp.get_attribute('data-keys') data_full_page_url = pluginOp.get_attribute('data-full-page-url') data_comment_num = pluginOp.get_attribute('data-comment-num') page = 1; while True: print (u'--- ページ %d ---' % page) # コメントページ取得用の URL を組み立て url2 = 'https://news.yahoo.co.jp/comment/plugin/v1/full/?' + \ 'origin=https%3A%2F%2Fheadlines.yahoo.co.jp' + '&' + \ 'sort=' + data_sort + '&' + \ 'order=' + data_order + '&' + \ 'page=' + str(page) + '&' + \ 'type=' + 't' + '&' + \ 'keys=' + data_keys + '&' + \ 'full_page_url=' + data_full_page_url + '&' + \ 'comment_num=' + data_comment_num + '&' + \ 'ref=' + '&' + \ 'bkt=' + '&' + \ 'flt=' + '&' + \ 'disable_total_count=' + '&' + \ 'compact=' + '&' + \ 'compact_initial_view=' + '&' + \ 'display_author_banner=' + 'off' + '&' + \ 'ua=' + 'Mozilla%2F5.0+(Windows+NT+6.3%3B+Win64%3B+x64)+AppleWebKit%2F537.36+(KHTML%2C+like+Gecko)+Chrome%2F58.0.3029.110+Safari%2F537.36' # コメントページ 取得 self.driver.get(url2) # 「返信」 リンクを click rep_links = self.driver.find_elements_by_css_selector('a.btnView.expandBtn') for rep_link in rep_links: rep_link.click() # 「以前のコメントを表示」 リンクを click # 返信コメントがすべて表示されると、リンクが非表示になる(is_displayed で判定) # それまでクリックを繰り返す view_links = self.driver.find_elements_by_css_selector('a.moreReplyCommentList') for view_link in view_links: while view_link.is_displayed(): view_link.click() time.sleep(2) # コメント 取り出し comments = self.driver.find_elements_by_css_selector('li[id^="comment-"]') for comment in comments: rootComments = comment.find_elements_by_css_selector('div.action article.root') if len(rootComments) == 0: continue rootComment = rootComments[0] comment_reply = {'user': rootComment.find_elements_by_css_selector('h1.name a')[0].text, 'date': rootComment.find_elements_by_css_selector('time.date')[0].text.strip(), 'comment': rootComment.find_elements_by_css_selector('p span.cmtBody')[0].text, 'agree': rootComment.find_elements_by_css_selector('a.agreeBtn em')[0].text, 'disagree' : rootComment.find_elements_by_css_selector('a.disagreeBtn em')[0].text } # 返信コメント 取り出し replyList = [] replys = comment.find_elements_by_css_selector('li[id^="reply-"]') for reply in replys: cmtBodies = reply.find_elements_by_css_selector('div.action article p span.cmtBody') if len(cmtBodies) == 0: continue replyList.append({'user': reply.find_elements_by_css_selector('h1.name a')[0].text, 'date': reply.find_elements_by_css_selector('time.date')[0].text.strip(), 'comment': cmtBodies[0].text, 'agree': reply.find_elements_by_css_selector('a.agreeBtn em')[0].text, 'disagree': reply.find_elements_by_css_selector('a.disagreeBtn em')[0].text }) comment_reply['replies'] = replyList yield comment_reply # 「次へ」を確認 nextLink = self.driver.find_elements_by_css_selector('ul.pagenation li.next a') if len(nextLink) > 0: time.sleep(1) page += 1 else: break def getTitle(self): return self.title if __name__ == '__main__': url = 'https://headlines.yahoo.co.jp/cm/main?d=20170526-00000005-withnews-ent' crawler = CommentCrawler() crawler.page(url) ''' crawler は以下の形式で yield してくる {user, date, comment, agree, disagree replies : [[user, date, comment, agree, disagree],・・・]} ''' for i, c in enumerate(crawler.crawl()): print (u'----- コメント %d --------------------------' % (i+1)) print ('%s %s' % (c['user'],c['date'])) print (c['comment']) print ('Y %s N %s' % (c['agree'], c['disagree'])) for j, r in enumerate(c['replies']): print ('') print (u'(返信 %d)' % (j+1)) print ('%s %s' % (r['user'],r['date'])) print (r['comment']) print ('Y %s N %s' % (r['agree'], r['disagree'])) print ('\n') print (crawler.getTitle()) |
実行すると 「おかあさんといっしょ」でサプライズ演出 一体、何が? NHKに秘密を聞いた のコメントが表示されます。
こんな感じです(一部抜粋)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
----- コメント 144 -------------------------- yui***** 2017/05/29 16:33 全然知らなかったぁ~ Y 0 N 0 ----- コメント 145 -------------------------- jen***** 2017/05/29 08:11 結構前から知ってたし、すでに2〜3回は目撃してる(笑) Y 35 N 16 (返信 1) ony***** 2017/05/29 11:02 いいなぁ~。 うちもずっとEテレつけっぱなしだけど、家事しながらだから、見たことない…。 23日のもこの記事で知って、ショック…。 見たかったなぁ~。 Y 1 N 0 |
保存
コメントを MongoDB に保存してみます。__main__ を次のようにすれば、保存されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
if __name__ == '__main__': url = 'https://headlines.yahoo.co.jp/cm/main?d=20170526-00000005-withnews-ent' crawler = CommentCrawler() crawler.page(url) from pymongo import MongoClient client = MongoClient('localhost', 27017) db = client.mydb for c in crawler.crawl(): db.yahoo_comment.insert_one(c) |