TF-IDF について簡単にまとめてみました。文書の分類などに使われるようです。
文書をベクトル化
文書の特徴をベクトルで表すことを考えてみます。
単純な方法として、単語の出現頻度を要素とするベクトルが考えられます。
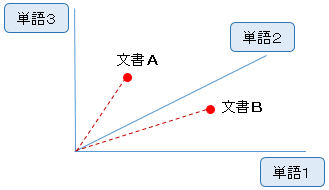
これでも、それなりに特徴を捉えてはいますが、たとえば「です」「ます」のように、どの文書にも存在する、ありふれた単語(さほど重要でない)に大きく引きずられてしまいます。
その弊害を避けるため、特定の文書にだけ現れる単語と、ありふれた単語に差をつけます。つまり、各単語の希少性を考慮にいれることを考えます。
そこで登場するのが TF-IDF です。
TF-IDF
TF は Term Frequency、単語の出現頻度
IIDF は Inverse Document Frequency、逆文書頻度(これが希少性)
単語の出現頻度と希少性をふたつ掛け合わせた値が TF-IDF で、下記の計算でもとめます。
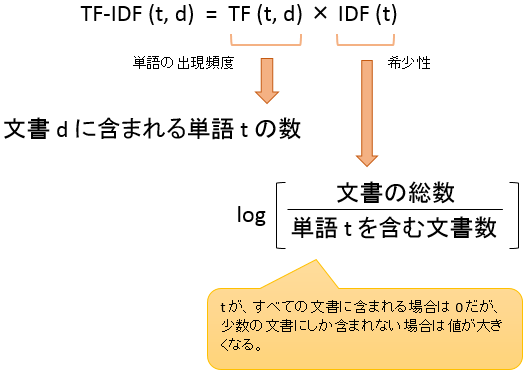
この式で、すべての文書と単語から TF-IDF を計算し、下記の文書ベクトルを求めます。
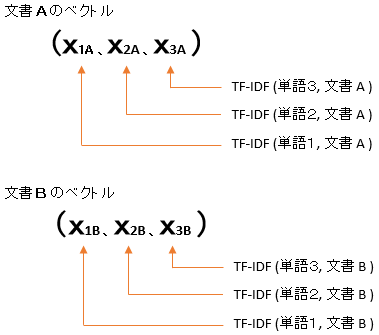
このベクトルを使って、たとえばクラスタリングを行ったり、文書の類似度を求めたりします。
python で
TfidfVectorizer
python で TF-IDF を求めるには scikit-learn の TfidfVectorizer が使えます。
ただし、独自に計算式が改良されており、下記の赤字部分が追加されています。
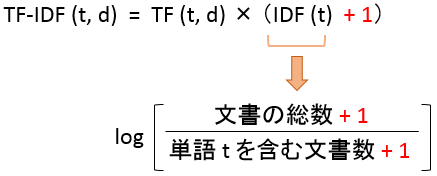
また、ベクトル長が 1 になるよう正規化された値が出力されます。
使ってみる
単語は 白、黒、赤 の 3種類、文書は 4 つです。
入力するのは、単語をスペースで区切った文書、いわゆる分かち書きされた文書です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
import numpy as np from sklearn.feature_extraction.text import TfidfVectorizer np.set_printoptions(precision=2) docs = np.array([ '白 黒 赤', # 文書1 '白 白 黒', # 文書2 '白 黒 黒 黒', # 文書3 '白' # 文書4 ]) vectorizer = TfidfVectorizer(use_idf=True, token_pattern=u'(?u)\\b\\w+\\b') vecs = vectorizer.fit_transform(docs) print vecs.toarray() #----------------------- # [[ 0.4 0.77 0.49] ← 文書1のベクトル # [ 0.85 0. 0.52] ← 文書2のベクトル # [ 0.26 0. 0.96] ← 文書3のベクトル # [ 1. 0. 0. ]] ← 文書4のベクトル #----------------------- |
行方向に文書、列方向に単語が並んでいます。
単語と列の対応は下記で確認できます。
|
1 2 3 4 5 6 7 |
for k,v in sorted(vectorizer.vocabulary_.items(), key=lambda x:x[1]): print k,v #------- # 白 0 # 赤 1 # 黒 2 #------- |
token_pattern
上記サンプルで、token_pattern=u'(?u)\\b\\w+\\b’ を指定しました。これは、文字列長が 1 の単語を処理対象に含めることを意味します。この指定をはずすと、長さ一文字の単語がまったくカウントされなくなります。
◇◇◇
以上が基本的な使い方です。これを踏まえて、次節でちょっと応用してみます。
クラスタリング
TF-IDF でベクトル化した文書をクラスタリングで分類してみます。K平均法を使います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
import numpy as np from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.cluster import KMeans docs = np.array([ '牛乳 を 買う', 'パン を 買う', 'パン を 食べる', 'お菓子 を 食べる', '本 を 買う', 'パン と お菓子 を 食べる', 'お菓子 を 買う', 'パン と パン を 食べる' ]) # # ベクトル化 # vectorizer = TfidfVectorizer(use_idf=True, token_pattern=u'(?u)\\b\\w+\\b') vecs = vectorizer.fit_transform(docs) print vecs.toarray() #----------------------------------------------------- # [[ 0. 0. 0.32 0. 0. 0.8 0.51 0. ] # [ 0. 0. 0.41 0.65 0. 0. 0.65 0. ] # [ 0. 0. 0.41 0.65 0. 0. 0. 0.65] # [ 0.69 0. 0.38 0. 0. 0. 0. 0.61] # [ 0. 0. 0.32 0. 0.8 0. 0.51 0. ] # [ 0.49 0.57 0.27 0.43 0. 0. 0. 0.43] # [ 0.69 0. 0.38 0. 0. 0. 0.61 0. ] # [ 0. 0.49 0.24 0.75 0. 0. 0. 0.37]] #----------------------------------------------------- # # クラスタリング # clusters = KMeans(n_clusters=2, random_state=0).fit_predict(vecs) for doc, cls in zip(docs, clusters): print cls, doc #---------------------------- # 0 - 牛乳 を 買う # 0 - パン を 買う # 1 - パン を 食べる # 1 - お菓子 を 食べる # 0 - 本 を 買う # 1 - パン と お菓子 を 食べる # 0 - お菓子 を 買う # 1 - パン と パン を 食べる #---------------------------- |
「○○を買う」と「○○を食べる」に分類されました。
野田 says:
この分野はまったくの初心者で初歩的な質問で申し訳ないのですが、
アドバイスいただければ幸いです。
本コラムのサンプルプログラムを参考にして、ある一覧表文書をベクトル化しました。
ベクトル化したデータをcsv形式に変換して、AzuleのMLにinputして機械学習させたいと考えております。
ここのプログラム例のvecsの行列式をcsv形式に変換する方法を教えていただきたく。
import csv
import xlsxwriter
import xlwt
を使って試行錯誤的にやっているのですがうまくいかず。
よろしく御教授ください。
野田です。 says:
野田です。
いろいろググったとっころ、
import numpy as np
data = vecs.toarray()
np.savetxt('vec.csv',data,delimiter=',')
で、できたっぽいです。
間違いあれば御指摘ください。
お騒がせしました。
tfidf says:
白 黒 赤
白 白 黒
白 黒 黒 黒
白
のように書かれてる例えばtxtファイルはどのように記述すればいいですか?