TwitterAPI を利用してツイートを大量にダウンロードしてみます。ダウンロードしたツイートを MeCab や Word2vec の元ネタにするつもりですが、とりあえず、データ取得の部分にしぼって書いてみます。
前半は API の基本事項の説明なので、そんなのもう知ってるよ、な方は 後半の 「大量にダウンロード」 にとんでください。
TwitterAPI とは
ツイートを投稿、閲覧するための API です。簡単に利用できるので、ツイッターにアクセスする独自アプリケーションを手軽に作成できます。
TwitterAPI を利用するには
- アプリケーションの登録
- 4つの認証キー取得
が必要にになります。
手順はいろいろなサイトで紹介されていますが、たとえば ここ で確認できます。
仕組み
REST形式で要求を出し、JSON形式で結果を受け取るのが基本的な仕組みです。用途に応じて様々なエンドポイントが定義されており、パラメータもそれぞれ異なります。いくつか例をあげると
●キーワードを指定してツイートを取得したければ
| URL | https://api.twitter.com/1.1/search/tweets.json |
| 必須パラメータ | q : 検索ワード |
●特定ユーザーのツイートをまとめて取得したければ
| URL | https://api.twitter.com/1.1/statuses/user_timeline.json |
| 必須パラメータ | user_id : ユーザーID または screen_name : スクリーン名(@で表示される名称) |
●ツイートを投稿したければ
| URL | https://api.twitter.com/1.1/statuses/update.json |
| 必須パラメータ | status : 投稿ツイート |
オプションのパラメータとして
- count
取得件数を指定します。 - max_id
ツイートID の最大値を指定します。
大量のツイートを取得する場合、一度に取得できるツイート数は限られているので、何度もリクエストを出すことになります。その際 max_id を指定すると、前回取得したツイートの次からを取得対象にできます。
取得データ
取得データは ステータスコード、ヘッダー部、テキスト部に別れます。
ステータスコード
API 呼出しの正常・異常終了はステータスコードで判定します。200 が正常終了を意味します。
ヘッダー部
ヘッダ部には以下に説明する制限情報がのっています。
たとえば、キーワードで検索する
は 15 分間に 180 回までと決まっており、この規定回数を超えてアクセスするとエラーになります(コード:429)。もちろん永遠にアクセスできないわけではなく、15 分毎にアクセス制限はリセットされます。
そうした制限に関する情報がヘッダ部にのっており、以下のキーで取得できます。
-
X-Rate-Limit-Remaining
アクセス可能回数 (アクセスするごとに -1 されていきます) -
X-Rate-Limit-Reset
アクセスが可能になるまでの時間 (アクセス可能回数が 0 になっても、この値の時間まで待てば回数はリセットされます)
補足
https://api.twitter.com/1.1/application/rate_limit_status.json
一発目の検索前にアクセス可能回数を調べるという手堅い実装をするなら、このエンドポイントが便利です。
こちらのソース の checkLimit で使ってます。
テキスト部
取得したツイートはテキスト部にのっています。テキスト部のフォーマットはエンドポイントによって差異があるので、ツイートを取り出す際は注意が必要です。
たとえば
- キーワード検索(https://api.twitter.com/1.1/search/tweets.json)の場合
⇒ テキスト部の statuses の下にツイートが置かれる - ユーザー名で検索(https://api.twitter.com/1.1/statuses/user_timeline.json)の場合
⇒ テキスト部の直下にツイートが置かれる
という違いがあります。
取得データ フォーマットイメージ
以下はキーワード検索時の取得データのフォーマット(ごく一部の抜粋)です。ユーザー名で検索した場合は statuses という項目そのものが存在せず、テキスト部直下にツイートがぶら下がっています。
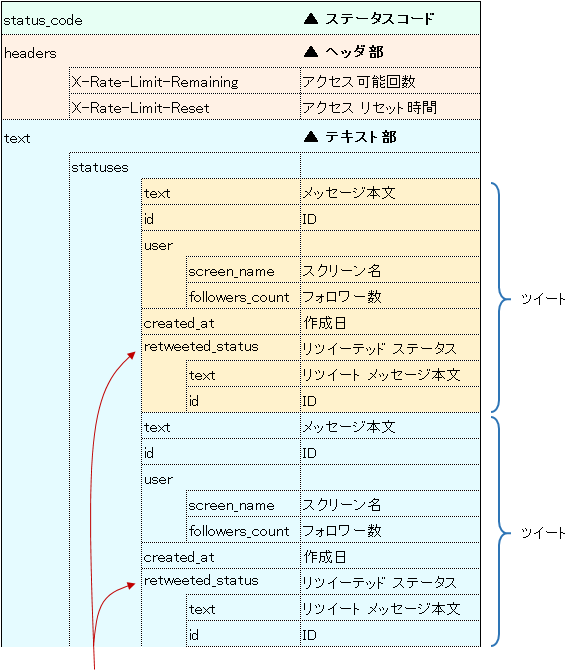
コピペ用
┗ X-Rate-Limit-Remaining
┗ X-Rate-Limit-Reset
┗ statuses
┗ text
┗ id
┗ user
┗ screen_name
┗ followers_count
┗ created_at
┗ retweeted_status
┗ text
┗ id
サンプル
簡単なサンプルをコーディングしてみます。
ツイート取得
以下で、”沖縄旅行” を含むツイートを 10 件取得できます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
# -*- coding: utf-8 -*- from requests_oauthlib import OAuth1Session import json import datetime, time, sys CK = '8uYOL8qfRB---------------' # Consumer Key CS = 'HFIcvU2nCB----------------------------------------' # Consumer Secret AT = '104137178-----------------------------------------' # Access Token AS = '4ViVoEMdiH-----------------------------------' # Accesss Token Secert session = OAuth1Session(CK, CS, AT, AS) url = 'https://api.twitter.com/1.1/search/tweets.json' res = session.get(url, params = {'q':u'沖縄旅行', 'count':10}) #-------------------- # ステータスコード確認 #-------------------- if res.status_code != 200: print ("Twitter API Error: %d" % res.status_code) sys.exit(1) #-------------- # ヘッダー部 #-------------- print ('アクセス可能回数 %s' % res.headers['X-Rate-Limit-Remaining']) print ('リセット時間 %s' % res.headers['X-Rate-Limit-Reset']) sec = int(res.headers['X-Rate-Limit-Reset'])\ - time.mktime(datetime.datetime.now().timetuple()) print ('リセット時間 (残り秒数に換算) %s' % sec) #-------------- # テキスト部 #-------------- res_text = json.loads(res.text) for tweet in res_text['statuses']: print ('-----') print (tweet['created_at']) print (tweet['text']) |
ツイート投稿
投稿は以下で OK。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# -*- coding: utf-8 -*- from requests_oauthlib import OAuth1Session import sys CK = '8uYOL8qfRB---------------' # Consumer Key CS = 'HFIcvU2nCB----------------------------------------' # Consumer Secret AT = '104137178-----------------------------------------' # Access Token AS = '4ViVoEMdiH-----------------------------------' # Accesss Token Secert session = OAuth1Session(CK, CS, AT, AS) url = 'https://api.twitter.com/1.1/statuses/update.json' res = session.post(url, params = {'status':u'TwitterAPI を使って投稿する'}) #-------------------- # ステータスコード確認 #-------------------- if res.status_code != 200: print ("Twitter API Error: %d" % res.status_code) sys.exit(1) |
基本事項の説明はここまでです。次節でデータのダウンロードに取りかかります。
大量にダウンロード
ここからが本題ですが、ツイートを大量に取得するためのプログラムを作ります。一回に取得できる件数は 100 とか 200 件程度の上限があるので、ループしながら API 呼出しを繰り返すことになります。ただし、回数制限があるので、ひたすら API を呼び続けるわけにはいかず、考慮が必要です。
方針として
- 「キーワードで取得」 と 「ユーザーを指定して取得」 の2機能を備える
- ツイートは一件づつ yield する
- 回数制限に到達したら、制限解除まで sleep し、解除後に再開する
ことにします。
クラスは3つ。
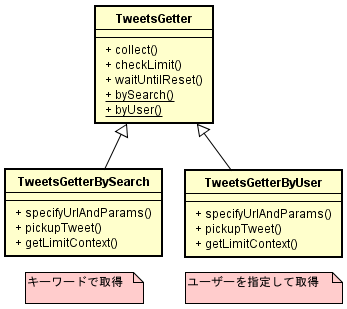
ソース
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 |
# -*- coding: utf-8 -*- from requests_oauthlib import OAuth1Session import json import datetime, time, sys from abc import ABCMeta, abstractmethod CK = '8uYOL8qfRB---------------' # Consumer Key CS = 'HFIcvU2nCB----------------------------------------' # Consumer Secret AT = '104137178-----------------------------------------' # Access Token AS = '4ViVoEMdiH-----------------------------------' # Accesss Token Secert class TweetsGetter(object): __metaclass__ = ABCMeta def __init__(self): self.session = OAuth1Session(CK, CS, AT, AS) @abstractmethod def specifyUrlAndParams(self, keyword): ''' 呼出し先 URL、パラメータを返す ''' @abstractmethod def pickupTweet(self, res_text, includeRetweet): ''' res_text からツイートを取り出し、配列にセットして返却 ''' @abstractmethod def getLimitContext(self, res_text): ''' 回数制限の情報を取得 (起動時) ''' def collect(self, total = -1, onlyText = False, includeRetweet = False): ''' ツイート取得を開始する ''' #---------------- # 回数制限を確認 #---------------- self.checkLimit() #---------------- # URL、パラメータ #---------------- url, params = self.specifyUrlAndParams() params['include_rts'] = str(includeRetweet).lower() # include_rts は statuses/user_timeline のパラメータ。search/tweets には無効 #---------------- # ツイート取得 #---------------- cnt = 0 unavailableCnt = 0 while True: res = self.session.get(url, params = params) if res.status_code == 503: # 503 : Service Unavailable if unavailableCnt > 10: raise Exception('Twitter API error %d' % res.status_code) unavailableCnt += 1 print ('Service Unavailable 503') self.waitUntilReset(time.mktime(datetime.datetime.now().timetuple()) + 30) continue unavailableCnt = 0 if res.status_code != 200: raise Exception('Twitter API error %d' % res.status_code) tweets = self.pickupTweet(json.loads(res.text)) if len(tweets) == 0: # len(tweets) != params['count'] としたいが # count は最大値らしいので判定に使えない。 # ⇒ "== 0" にする # https://dev.twitter.com/discussions/7513 break for tweet in tweets: if (('retweeted_status' in tweet) and (includeRetweet is False)): pass else: if onlyText is True: yield tweet['text'] else: yield tweet cnt += 1 if cnt % 100 == 0: print ('%d件 ' % cnt) if total > 0 and cnt >= total: return params['max_id'] = tweet['id'] - 1 # ヘッダ確認 (回数制限) # X-Rate-Limit-Remaining が入ってないことが稀にあるのでチェック if ('X-Rate-Limit-Remaining' in res.headers and 'X-Rate-Limit-Reset' in res.headers): if (int(res.headers['X-Rate-Limit-Remaining']) == 0): self.waitUntilReset(int(res.headers['X-Rate-Limit-Reset'])) self.checkLimit() else: print ('not found - X-Rate-Limit-Remaining or X-Rate-Limit-Reset') self.checkLimit() def checkLimit(self): ''' 回数制限を問合せ、アクセス可能になるまで wait する ''' unavailableCnt = 0 while True: url = "https://api.twitter.com/1.1/application/rate_limit_status.json" res = self.session.get(url) if res.status_code == 503: # 503 : Service Unavailable if unavailableCnt > 10: raise Exception('Twitter API error %d' % res.status_code) unavailableCnt += 1 print ('Service Unavailable 503') self.waitUntilReset(time.mktime(datetime.datetime.now().timetuple()) + 30) continue unavailableCnt = 0 if res.status_code != 200: raise Exception('Twitter API error %d' % res.status_code) remaining, reset = self.getLimitContext(json.loads(res.text)) if (remaining == 0): self.waitUntilReset(reset) else: break def waitUntilReset(self, reset): ''' reset 時刻まで sleep ''' seconds = reset - time.mktime(datetime.datetime.now().timetuple()) seconds = max(seconds, 0) print ('\n =====================') print (' == waiting %d sec ==' % seconds) print (' =====================') sys.stdout.flush() time.sleep(seconds + 10) # 念のため + 10 秒 @staticmethod def bySearch(keyword): return TweetsGetterBySearch(keyword) @staticmethod def byUser(screen_name): return TweetsGetterByUser(screen_name) class TweetsGetterBySearch(TweetsGetter): ''' キーワードでツイートを検索 ''' def __init__(self, keyword): super(TweetsGetterBySearch, self).__init__() self.keyword = keyword def specifyUrlAndParams(self): ''' 呼出し先 URL、パラメータを返す ''' url = 'https://api.twitter.com/1.1/search/tweets.json' params = {'q':self.keyword, 'count':100} return url, params def pickupTweet(self, res_text): ''' res_text からツイートを取り出し、配列にセットして返却 ''' results = [] for tweet in res_text['statuses']: results.append(tweet) return results def getLimitContext(self, res_text): ''' 回数制限の情報を取得 (起動時) ''' remaining = res_text['resources']['search']['/search/tweets']['remaining'] reset = res_text['resources']['search']['/search/tweets']['reset'] return int(remaining), int(reset) class TweetsGetterByUser(TweetsGetter): ''' ユーザーを指定してツイートを取得 ''' def __init__(self, screen_name): super(TweetsGetterByUser, self).__init__() self.screen_name = screen_name def specifyUrlAndParams(self): ''' 呼出し先 URL、パラメータを返す ''' url = 'https://api.twitter.com/1.1/statuses/user_timeline.json' params = {'screen_name':self.screen_name, 'count':200} return url, params def pickupTweet(self, res_text): ''' res_text からツイートを取り出し、配列にセットして返却 ''' results = [] for tweet in res_text: results.append(tweet) return results def getLimitContext(self, res_text): ''' 回数制限の情報を取得 (起動時) ''' remaining = res_text['resources']['statuses']['/statuses/user_timeline']['remaining'] reset = res_text['resources']['statuses']['/statuses/user_timeline']['reset'] return int(remaining), int(reset) if __name__ == '__main__': # キーワードで取得 getter = TweetsGetter.bySearch(u'渋谷') # ユーザーを指定して取得 (screen_name) #getter = TweetsGetter.byUser('AbeShinzo') cnt = 0 for tweet in getter.collect(total = 3000): cnt += 1 print ('------ %d' % cnt) print ('{} {} {}'.format(tweet['id'], tweet['created_at'], '@'+tweet['user']['screen_name'])) print (tweet['text']) # |
このまま実行すれば “渋谷” をふくむツイートが 3000 件取得できます。
コメントを入れ替えれば “AbeShinzo” さんのツイートが取得できます。
オプション
collect メソッドの引数で以下の 3 点が指定可能。
- total : 取得件数
デフォルト -1 (無制限に取得。ただし Twitter 側の設定する上限がある) - onlyText : メッセージ本文だけ取得する
デフォルト False - includeRetweet : リツイートを含める
デフォルト False
エラー対策
サーバー側に起因するなんらかの理由でエラーが発生する場合があります。以下、対処法です。
Service Unavailable
status_code:503
サーバー側の処理が追いつかない場合に発生します。しばらく sleep してアクセスを再開すれば問題ありません。必要な sleep 時間はサーバーの状況によると思いますが、今まで見た範囲では 30 秒の sleep で大丈夫でした。
Too Many Requests
status_code:429
180回/3分 等の回数制限を無視してアクセスすると発生します。
X-Rate-Limit-Remaining を確認しながらアクセスすれば通常は発生しません。
正しい手順として、X-Rate-Limit-Remaining が 0 になった場合は X-Rate-Limit-Reset まで sleepします。ただし、sleep 時間が微妙にサーバーとずれる可能性があるため、アクセスを再開する前に下記のエンドポイント
で
reset (アクセスが可能になるまでの時間)
を確認します。
X-Rate-Limit-Remaining が入ってない
理由は不明ですが、レスポンスに X-Rate-Limit-Remaining が入ってないことが稀にあります。そうしたケースでは、下記のエンドポイント
で
reset (アクセスが可能になるまでの時間)
を確認します。
ogawa says:
参考にさせていただいてます。ありがとうございます。
最後のprint文、括弧が無いようです。
管理人 says:
あ、抜けてますね。しかも、ところどころ。。。
直しました。
2.7 で動かしてるので、すぐ括弧を忘れてしまいます。
ありがとうございました。
ogawa says:
2.7!そうでした。すいません。大変具体的でありがたいです。いつもありがとうございます。
ik says:
プログラム大変参考にさせてもらっています。
質問なのですが
idを取得してidの人の自己紹介文を取得することは可能ですか?
管理人 says:
こんな感じでしょうか。
① ツイートから id を取得する
tweet['id']
② id からユーザー情報を取得する(別途、リクエスト)
url = 'https://api.twitter.com/1.1/users/show.json'
params = {'user_id':'xxxxxxxxx'}
↑
①で取得したやつ
res = session.get(url, params = params)
③ 自己紹介を取りだす
t = json.loads(res.text)
print (t['description'])
======================
ちなみに
安倍さんの自己紹介はこれで取得できました。
url = 'https://api.twitter.com/1.1/users/show.json'
params = {'user_id':'468122115'}
res = session.get(url, params = params)
t = json.loads(res.text)
print (t['description'])
tas says:
分かりやすい記事をありがとうございます。
大量にツイートを取得する際は最近のツイートしか取得できないという使用でしょうか。
キーワードによっては取得件数が少ししか取れないものもあるようでして
お願いします。
管理人 says:
tas さん、どうも。
ネットの情報ですが、APIでは過去1週間のツイートしか取れないようです。
キーワードによっては、ほとんどツイートがないケースもあるかもしれませんね。
tas says:
管理人様
回答頂きありがとうございます。
ツイートID で過去の記事を取得するとかありますね。
streamingAPI をずっと動かしつづけるしかないのでしょうか・・・(T_T)
匿名 says:
機械学習で使うために参考にさせてもらってます!とても助かります!
管理人 says:
コメント、どうもありがとうございます。
励みになります。(最近さぼり気味ですが ;)
yu says:
管理人様
tweetの投稿された位置情報(投稿場所情報)を同時に取得するにはどのようにすればよろしいでしょうか?
管理人 says:
yuさん、こんにちわ
coordinates という項目に経度、緯度が入るようです。
掲載ソースの場合、こうなります。(インデントがうまく入ってませんが)
if tweet['coordinates'] is not None:
print (tweet['coordinates']['coordinates'][0]) # 経度
print (tweet['coordinates']['coordinates'][1]) # 緯度
位置情報付きでつぶやく人は少ないので、実際に coordinates に値が入るツイートも少ないようです。
SUSUMU says:
はじめましてこんにちは。
自分は研究でTwitterのツイート内容の解析について勉強中なのですが、テキストに実行結果を出力する方法がいまいちわからないので教えていただけませんか?
管理人 says:
SUSUMUさん、こんにちは
テキストファイルに出力ということでしたら、こんな感じでできると思います。
for ループのインデントが入ってませんが、そこは付け足してください(f.write の箇所)。
import codecs
getter = TweetsGetter.bySearch(u'渋谷')
f = codecs.open('/tmp/tweets.txt', 'w', 'utf-8')
for tweet in getter.collect(total=3):
f.write('——————————————–')
f.write('\n')
f.write(str(tweet['id']))
f.write('\n')
f.write(tweet['created_at'])
f.write('\n')
f.write(tweet['user']['screen_name'])
f.write('\n')
f.write(tweet['text'])
f.write('\n')
f.close()
SUSUMU says:
返信ありがとうございます。
御礼の言葉が遅くなりすみませんでした。
ayato says:
こちらのプログラム私も参考にさせて頂いているのですが以下のようなエラーが改善できません。
Traceback (most recent call last):
File "text.py", line 242, in
f = codecs.open('/tmp/tweets.txt', 'w', 'utf-8')
File "C:\Program Files\Python35\lib\codecs.py", line 895, in open
file = builtins.open(filename, mode, buffering)
FileNotFoundError: [Errno 2] No such file or directory: '/tmp/tweets.txt'
何かお力添え頂ければ幸いです。
管理人 says:
tmp ディレクトリがないのでは?
renaco says:
管理人さま
とてもわかりやすい記事をありがとうございます.
当方超初心者で野暮な質問だとは重々承知なのですが
Twitter Streaming APIとはまた別のAPIなのでしょうか?
それとも上記APIをPHPではなくPythonで動かしてみた,とうことなのでしょうか?
管理人 says:
renaco さん、こんにちわ。
ここで紹介した TwitterAPI は過去のツイートを取得するものです。
Twitter Streaming API は、今現在つぶやかれたツイートをリアルタイムで取得するものです。動かしっぱなしにしとけば最新ツイートがどんどん送られてきます。
管理人 says:
インデントが入ってないですけど、Streaming はこんな感じで動くようです。
import requests
import json
from requests_oauthlib import OAuth1
CK = '8uYOL8qfRB—————'
CS = 'HFIcvU2nCB—————————————-'
AT = '104137178—————————————–'
AS = '4ViVoEMdiH———————————–'
url = "https://stream.twitter.com/1.1/statuses/filter.json"
auth = OAuth1(CK, CS, AT, AS)
r = requests.post(url, auth=auth, stream=True, data={'track' : u'渋谷'})
for line in r.iter_lines():
if len(line) == 0:
continue
tweet = json.loads(line)
print ('—————- ')
print ('{} {}'.format(tweet.get('created_at'), '@'+tweet.get('user').get('screen_name')))
print (tweet.get('text'))
aris says:
初めまして。
こちらのプログラム大変参考にさせて頂いております。
初心者の質問で申し訳ないのですが、取得したツイートを形態素解析してExcelで表にしたいと考えているのですが、こちらにそういったプログラムを組み込む事は可能でしょうか?
もし可能であれば、方法等ご教授頂けますと幸いです。
管理人 says:
aris さん、こんにちわ。
形態素解析は janome を使うのが手軽だと思います。
excel出力はやったことがないのでよく分かりませんが、検索すればいろいろなライブラリが出てくるようです。
どんな表を作るのかにもよりますが、大体こんな流れではないでしょうか。
① tweet['text']を janome に渡して単語に分解、
② その結果を集計(単語のカウント等)
③ excel に出力
aris says:
お返事遅れて申し訳ありません。
色々解説下さりありがとうございます。
janome等調べて試行錯誤してみようと思います。
また知恵をお貸しいただければ幸いです。
gg says:
わかりやすい記事で初心者の私も大変参考になっています。
質問なのですが画像付きのツイートのみを取得し画像のidを取得するといったことは可能でしょうか?
管理人 says:
ggさん、こんにちわ。
詳細は未確認ですが、検索キーに filter:media と付け加えると画像や動画付きのツイートが取得できるようです。
getter = TweetsGetter.bySearch(u'渋谷 filter:media')
ymk says:
初心者でもわかりやすい記事で参考にさせていただいており、大変勉強になります。
お忙しいところ大変申し訳ないのですが、プログラム作成に手こずっており、自分で解決する事ができなかったため、教えていただければと思いコメントさせていただきました。
現在、ツイートを30000件取得し、ツイート3000件ずつテキストに保存をするプログラムを組もうとしています。
管理人様のプログラムを実行するとAPIアクセス回数は100件に2回〜3回ほどなのですが、下記のプログラムのようにif文を付け加えると極端に増えて10回以上アクセスしてしまい、ツイートを取得するのに時間がかかってしまいます。アクセス回数を減らすにはどうしたらいいでしょうか、お時間あるとき二返信くださると大変助かります。
if __name__ == '__main__':
# キーワードで取得
getter = TweetsGetter.bySearch(u'リセット')
cnt2 = 1
cnt = 0
cnt3 = 0
count = 0
f = codecs.open('tweet.txt', 'w')
for tweet in getter.collect(total=30000):
cnt += 1
cnt3 += 1
f.write('————————————-'+str(cnt))
f.write('\n')
f.write(tweet['text'].strip())
f.write('\n')
if cnt % 3000 == 0 and not(cnt3 ==30000):#3000件ごとにファイルを作る、3000件目はテキストファイルを作らない
cnt2 += 1
cnt = 0
f.close
f = codecs.open('tweet'+str(cnt2)+'.txt', 'w')#次のファイルに移るときcnt2をカウントしてファイル名にする
elif cnt3 == 30000:
f.close
else:#if文実行何回で1回アクセスしているかみる
count += 1
print(count)
f.close
管理人 says:
ymk さん、こんにちわ。
拝見したところ、else の処理は cnt が 1 から 2999 の場合、常に通るように見受けられます。ということは、closeしたファイルに write していることになります。
その辺が影響して挙動がおかしくなっているのではないでしょうか。
さく says:
大変わかりやすい記事をありがとうございます。
tweetを大量に取得したいと思い、collectのtotal=500,000にしてみたところ、wait表示が表示されず、9400件ほどしか取れていないのに関わらずプログラムが実行完了してしまいます。
mongoの方の問題だとも思ったのですが、DB名を変えても同様の動作になってしまいます。また、一週間分しかAPIでは取れないからかとも考えたのですがtotal=50,000だと問題なく動くのでこれも原因ではないと思いました。どうしたら挙動が改善するのかお時間のある時にでもアドバイスをいただけると嬉しいです。
管理人 says:
さく さん、こんにちわ。
もしエラー表示がない状態で終了したのならデータがそれだけしかなかったのだと思いますが ??? ちょっと判りかねます ???
さく says:
管理人さま
早速のご返信ありがとうございました。
また、別件なのですがcollectの値を指定しなければ一週間分の全データを取得することは可能でしょうか?
度々質問をしてしまい、申し訳ありません。
ゆき says:
初めまして。
現在独学でpythonのスクレイピングを学んでいたところでしたので、
掲載頂いた記事がとても分かりやすく非常に感謝しております。
「大量にダウンロード」の章で記載いただいたプログラムを自分で作成してみたところ、
以下のエラーがどうしても消えず、困っています。。
requests.exceptions.MissingSchema: Invalid URL 'https//api.twitter.com/1.1/application/rate_limit_status.json': No schema supplied. Perhaps you meant http://https//api.twitter.com/1.1/application/rate_limit_status.json?
URLが有効ではないエラーなのかなと思っているのですが、
どのように改善したら良いか私の方では分からない状況でして、、
エラーの回避方法についてもし何かお分かりでしたらご教授いただけますと大変助かります!
管理人 says:
ゆきさん、こんにちわ
httpsの後ろ、コロン':'が抜けてますね
ゆき says:
管理人さん
ありがとうございます!
初歩的なミスで大変申し訳ございませんでした・・
まさおか says:
こんにちは。
python学習中のため、いつも参考にしております。
一つお聞きしたいのですが、このプログラムに「リツイート数」、「いいね数」
を実装することは可能でしょうか。
管理人 says:
まさおかさん、こんにちわ
twitter の以下サイトにAPI検索で取得可能なデータが載っています。
ttps://developer.twitter.com/en/docs/tweets/search/api-reference/get-search-tweets
「Example Response」に記載があれば、取り出すことができます。
takenoko says:
管理人 様
はじめまして。基礎から勉強中のpython初心者です。
Twitterの分析をしたくこのプラグラムにたどり着きました。
大量にダウンロードのコードを使用して取得は出来るのですが、
結果をtextに吐き出したく、以前の質問に同内容を拝見しましたが、
どこにwrite等のtext書き込みコードを入れて良いのかご教示お願いします。
色々調べたのですが、、初歩的な質問ですいません。
何卒、宜しくお願いします。
管理人 says:
takenoko さん、こんにちわ
'__main__' 以下を
http://ailaby.com/twitter_api/#comment-2671 の内容で置き換えれば動くと思います。
(事前にtmpディレクトリを作ってから)
takenoko says:
管理人 様
ご返信ありがとうございます。以下に書き換えてみましたが動かず。。
置き換えの方法や記述の仕方に問題があったのか、度々申し訳ございません。
ご指摘頂けますと幸いです。以下アフターの235行以下コードになります。
if __name__ == '__main__':
import codecs
getter = TweetsGetter.bySearch(u'渋谷')
f = codecs.open('/tmp/tweets.txt', 'w', 'utf-8')
for tweet in getter.collect(total=1000):
f.write('——————————————–')
f.write('\n')
f.write(str(tweet['id']))
f.write('\n')
f.write(tweet['created_at'])
f.write('\n')
f.write(tweet['user']['screen_name'])
f.write('\n')
f.write(tweet['text'])
f.write('\n')
f.close()
管理人 says:
ファイル出力がうまくいかないようですが、原因はちょっと判りかねます。その辺に関するノウハウはネット上で十分得られると思いますので、そちらを参考にしてください。まず基本的な知識を習得されるのが早道かと思います。
takenoko says:
管理人様
ご指摘感謝します。もう少し勉強してみます!
ありがとうございました。
匿名 says:
管理人様
こちらのコードを参考にコードを作成したところ、非常に参考になり助かりました。
1点伺いたいのですが、複数条件を指定する(たとえば、"渋谷"かつ"ハチ公")場合、」どのように記述すればよいのでしょうか?
管理人 says:
匿名さん
TweetsGetter.bySearch(u'渋谷 ハチ公') でできます。
匿名 says:
初歩的な質問で申し訳ないのですが、jsonのimportができません。
ターミナルからのぱけーじインストールコマンドは何を使っているか教えていただきたいです。
管理人 says:
python2.7 には最初から json が入っているようです。python の古いバージョンの場合は simplejson というものをインストールするそうです。詳しくはネットで検索してみてください。
潜水艇金槌 says:
管理人様
はじめまして。
素人質問で恐縮なのですが,一点ご教示願えませんか?
「APIで収集できるのは1週間分」とのことですが,
1週間分のデータを収集し終えた後も,
引き続き新たなtweetを取得し続けるように
することもできるのでしょうか…?
急ぎませんので,ご都合のよろしいときに
ご教示いただけますと幸いです。
管理人 says:
潜水艇金槌さん、こんにちわ。
質問の意図と少し違うかもしれませんが、Streaming API を使うと最新のツイートをリアルタイムで取得し続けることができます。
こちらで少し触れています。
http://ailaby.com/twitter_api/#comment-3284
http://ailaby.com/twitter_api/#comment-3285
潜水艇金槌 says:
管理人様
こんにちは。
お忙しい中,お返事いただいたにもかかわらず,
こちらからの反応が遅くなってしまい申し訳ありません。
ご丁寧にご教示下さりありがとうございます。
Streaming APIは6月に使えなくなるという話を風のうわさで聞いたのですが,
これに代わるものなどご存知ないでしょうか…?
(また,実際に使ってみたのですが,「全体の1%」からtweetを取得しているためか,思ったほどのデータが得られず…)
こちらに関しましても,
ご都合のよろしいタイミングでご教示いただけますと幸いです。
はな says:
管理人様
はじめまして。
現在研究のためにツイートを集めています。
そのなかで管理人様の作成したプログラムを参考にしました。
本当にありがとうございます。
今回は質問があり連絡させていただきました。
管理人様のプログラムを複数のユーザーのツイートを順次取得していくように変更しました。
そのなかでToo Many Requestsでエラーが起こります。(関数checkLimit内のif res.status_code != 200)
エラー対策として管理人様が remaining 、resetを確認すると書いていますがどうすればプログラムを変更したらいいのかわかりません。
速度制限でエラーを起こさず、可能になるまで待つ様に変える為にはどうしたらいいでしょうか。
ご多忙のところ恐縮ですが、ご返答いただければ幸いです 。
よろしくお願い致します。
管理人 says:
はなさん、こんにちわ。
> エラー対策として remaining 、resetを確認する
これは、tweets.json または user_timeline.json の取得で Too Many Requests が発生した場合の対策です。rate_limit_status.json に関しては当てはまりません。
あまりキレイなやり方ではありませんが、Too Many Requests 発生時に15分以上の sleep を入れて continue すれば、とりあえず動くと思います。
ただ、このやり方だと sleep が頻発するかもしれません。
キレイに直すとすれば、TweetsGetter.byUser の引数としてユーザー名の配列を渡し、collect 内部でユーザー名を切り替えていく形が考えられます。こちらは大がかりな修正になりそうですが。。。
はな says:
管理人様
こんにちは。
お早い対応有難うございます。
さらにとても分かりやすく教えて頂いて、重ねて心より感謝申し上げます。
>TweetsGetter.byUser の引数としてユーザー名の配列を渡し、collect 内部でユーザー名を切り替えていく形
こちらはcollect内を変更するのは怖くて出来ないので諦めます。。。
提案してくださったのに申し訳ありません。ありがとうございます。
>Too Many Requests 発生時に15分以上の sleep を入れて continue
こちらを行おう為に下記の様に変更しました。
if res.status_code == 429:
time.sleep(900)
continue
elif res.status_code != 200:
raise Exception('Twitter API error %d' % res.status_code)
教えて頂いた方法とあっているか不安ですが、
今のところエラーを起こさず動き続けています。本当にありがとうございます!
ご迷惑をおかけしないように頑張りますが、
また質問が出来てしまった際にはどうかよろしくお願いいたします。
はな says:
管理人様
こんにちは。
またの質問失礼いたします。
今日またツイートを取得しようと思い実行したところ下記のエラーが起こりました。
意味がわからなかった為とりあえずもう一度実行したところ動きました。
しかし途中でエラーが起こりました。同様のエラー文でした。
File "autosearch.py", line 107, in collect
self.checkLimit()
File "autosearch.py", line 136, in checkLimit
remaining, reset = self.getLimitContext(json.loads(res.text))
File "autosearch.py", line 193, in getLimitContext
remaining = res_text['resources']['search']['/search/tweets']['remaining']
KeyError: 'search'
このエラー文はどういことでしょうか?
ツイートを取得しすぎてAPI側が制限をかけてきているのかなとヒヤヒヤしています。。。
お忙しいとは思いますが、ご返答いただければ幸いです 。
よろしくお願い致します。
管理人 says:
KeyError: 'search' は、レスポンスの json 内に search 要素が無いという意味です。
ユーザーを指定してツイートを取得する …ByUserクラス を動かしているのだと思いますが、エラーの発生個所はキーワードで検索する …BySearchクラス 側のようです。ちょっと変ですね。
継承関係がおかしくなってるのかもしれませんが、詳しい原因はよくわかりません。修正箇所を見直してみてください。
案外、TweetsGetterBySearch クラスをばっさり削除すると動くかもしれません。
はな says:
管理人様
早速のお返事感謝致します。
エラーの意味からわからなかったのですが、
管理人様のおかげで理解出来ました。
ただ修正すべきところが明確にはわかっていません。
頑張って修正をかけていきたいと思います。
また、TweetsGetterBySearchクラスををばっさりいったのも試してみます。
毎度質問にお答えいただき本当に感謝しています。
有難うございます。今後また質問するかもしれません。
どうかその時もよろしくお願い致します。
ari says:
管理人様 はじめまして。
いきなりで申し訳ないのですが一つ質問があります。
”沖縄旅行”のサンプルコードを参考にさせていただいたのですが、until sinceなどを用いて日付け指定をしたい場合はどこに挿入すればよいのか、教えていただきたいです。
管理人 says:
ari さん、こんにちわ
until は params に追加すれば指定できると思います。
params = {'q':u'沖縄旅行', 'count':10, 'until':'2018-06-24'}
(試してないので確実ではありませんが)
since は残念ながら API で指定できないようです。
下記のサイトにAPIで使用可能なパラメータが載っています。
ttps://developer.twitter.com/en/docs/tweets/search/api-reference/get-search-tweets
ツイートの created_at に日付が入っているので、それを取りだして since until を判定してもいいかもしれません。
潜水艇金槌 says:
管理人さま
こんにちは。
以前質問させていただきました潜水艇金槌です。
その節は,ご丁寧にご回答下さりありがとうございました。
その後,RestAPIを用いてtweetを収集するべく,再び
貴サイトを参考にさせていただいております。
スクリプトに手を加えながらいろいろと実行しているのですが,
1点ご教示いただけませんか?
retweetも含めて収集したい場合は,
以下二か所の【False】を【True】に換えて実行すればよいのでしょうか…?
def collect(self, total = -1, onlyText = False, includeRetweet = False):
if (('retweeted_status' in tweet) and (includeRetweet is False)):
素人質問で恐縮なのですが,
お時間おありの際にご指導いただけますと幸いです。
管理人 says:
潜水艇金槌 さん、こんにちわ
それでも動くのですが、通常は collectメソッド側ではなく呼び出し側を修正します。
includeRetweet = True を下記のように追加してください。
getter.collect(total = 3000, includeRetweet = True)
潜水艇金槌 says:
管理人さま
こんにちは。
お忙しい中にもかかわらず,
ご丁寧にご回答下さりありがとうございます。
ご教示いただいたように修正し,実行しましたところ,
無事,RTも取得することができました。
ありがとうございます。
また不明点が出てきましたら,
お手数おかけして申し訳ありませんが
ご教示いただけますと幸いです。
P.p says:
管理人様
こんばんは。
python学習の参考としてサイトを利用させていただいております。
retweeted_statusをMongoDBに保存しようと、
for tweet in tweets:
tweet2 = {}
tweet2['retweeted_status'] = tweet['retweeted_status']
db.xxxxxx.insert(tweet2)
としましたが、keyerror:retweeted_statusとなりうまくいきません。
ご教授いただけると幸いです。
P.p says:
追記
retweeted_statusは、リツイートのみにしか付加されないので保存時にtweetをそのままinsertしました。
しかし、retweeted_statusだけ取り出そうとprint(record['retweeted_status'])としてもやはりKeyErrorが出てしまいます。
管理人 says:
P.p さん
record['retweeted_status'] の前に retweeted_status の存在チェックが必要なのでは
匿名 says:
管理人様
お忙しいところ、返信感謝いたします。
print['record']をして、retweeted_statusの存在が確認できている場合でも、KeyErrorと出てしまいます。
twitter開発者ドキュメントをみても、retweeted_statusが何かの入れ子になっているわけではなさそうなので、なぜキーが存在しないか不明でした。
匿名 says:
申し訳ございません。自己解決いたしました。
K.K says:
管理人様
こちらのコードを参考に、Twitterデータ取得をさせていただいているpython初学者です。
いつも、大変お世話になっております。
1ヶ月ほど前までは正常に作動していたのですが、
—————————————————————————
gaierror Traceback (most recent call last)
~/.pyenv/versions/anaconda3-5.2.0/lib/python3.6/site-packages/urllib3/connection.py in _new_conn(self)
140 conn = connection.create_connection(
–> 141 (self.host, self.port), self.timeout, **extra_kw)
142
~/.pyenv/versions/anaconda3-5.2.0/lib/python3.6/site-packages/urllib3/util/connection.py in create_connection(address, timeout, source_address, socket_options)
59
—> 60 for res in socket.getaddrinfo(host, port, family, socket.SOCK_STREAM):
61 af, socktype, proto, canonname, sa = res
~/.pyenv/versions/anaconda3-5.2.0/lib/python3.6/socket.py in getaddrinfo(host, port, family, type, proto, flags)
744 addrlist = []
–> 745 for res in _socket.getaddrinfo(host, port, family, type, proto, flags):
746 af, socktype, proto, canonname, sa = res
gaierror: [Errno -2] Name or service not known
というエラーが出てしまって、データ取得が出来ないです・・・。
こちら、管理人様のコードに問題というよりは、私のローカル環境の問題でしょうか・・・?
自分でも調べてみたのですが、プログラミング初心者のせいか、解決策が分かっていません。
もしご助言いただければ幸いです。
管理人 says:
K.Kさん、こんにちは
はっきりとは判りませんが、socket関連でエラーになっているので、通信環境に問題があるのだと推測します。
twitterのサーバーが見えていない状態だと思います。
K.K says:
管理人様、ご返信くださりありがとうございます。
リモートサーバにSSH接続した状態でデータ取得しようとしたところ上記のエラーになり、個人のローカルでデータ取得をしたところ問題なく取得が出来ました。
原因はまだ特定できていないのですが、とりあえずは取得できています。
R.K says:
管理人様
日頃からこちらのコードを参考にさせていただいて、大変お世話になっております。
totalに大きな値(例えば50000)を指定して実行したところ、今月分のツイートは取得できるのですが、月をまたいでツイートの取得ができませんでした(今月分のツイートを取得し終わると、totalで指定した数に達していなくてもプログラムが終了してしまう)。また、sinceやuntilといった検索方法も試しましたが、先月から前のツイートの取得ができませんでした。
質問なのですが、先月から前のツイートの取得は可能なのでしょうか?
お手数おかけして申し訳ありませんが、
ご助言いただけたら幸いです。
管理人 says:
R.Kさん、こんにちは
ツイートは1週間ぶんしか取得できないようです。
ttps://developer.twitter.com/en/docs/tweets/search/api-reference/get-search-tweets
の until の説明欄で確認してみてください
R.K says:
返信ありがとうございます!
リンク先の説明欄、参考にさせていただきます。
kz says:
管理人様
初めまして、こちらのコードを重宝させていただいている者です。
回数制限に達した後、休止状態を経て、再度ツイートの収集を再開するタイミングで
ConnectionError: ('Connection aborted.', OSError("(10060, 'WSAETIMEDOUT')"))
というエラーが出ます。
解決方法に全く不明なのですが、何かご存じでしょうか。
お忙しいところ、全くの素人質問で申し訳ありませんが、よろしくお願いいたします、
C.Y says:
管理人様
Twitterデータ取得でこちらのコードを参考にさせていただいております。
画像つきのツイートの取得方法はキーワードの後ろにfilter:mediaをつけることで取得できるのですが、画像をダウンロードして保存する方法を教えていただけないでしょうか。
お手数おかけして申し訳ありませんが、
ご助言いただけたら幸いです。
KDN says:
管理人様
上記のコードを実行すると、tweetの全文を取得できないことがあるのですが、全文を取得するためにはどうすればよろしいでしょうか?
paramsにtweet_mode=extendedを追加してもうまくいきません。
お手数ですが、ご助言いただけたら幸いです。
よろしくお願いいたします。
KDN says:
管理人様
すみません。解決しました。
tweet_mode=extendedにすることで、full_textがkeyになっているので、textをfull_textにすればいい話でした。。。
classlacia says:
機械学習に十分な大量のツイートを取得するのに詰まっていたとき、こちらの記事に出会って解決することができました。
当時は時間がなくきちんとコードの中身を消化せずコピペしてしまったのですが、今は学習用に参考にさせて頂いています。
即座に実行できるコードだけでなく、丁寧な解説が記載されているので、実用と学習の両方のニーズを満たす素晴らしい記事です。
ありがとうございます
時系列全てが動くコードに感謝 says:
管理人さん
理解の時系列において、全てが動くコードを掲載いただき、大変感謝いたします。
他の方もコメントしておられますが、
プログラムの技術と、他人に教える技術はそれぞれ別物で、両方お持ちの方は大変少ないです。
(私見です。お気を悪くされる方がおられたら申し訳ございません。)
プログラムの羅列ではなく、教える文章の記載は大変かとは思いますが、
今のスタイルを続けていただけると、学習者として大変ありがたいです。
また、各種コメントに対する姿勢も只々称賛しています。
ありがとうございます
Aoi says:
管理人様
初めまして。こちらのコードを参考にtwitterのデータ収集を行っているpython初心者です。
コードを実行した際に、恐らくですが絵文字が原因でエラーが出てしまいます。
ツイート本文から絵文字を消去してテキスト化するにはどうすれば良いでしょうか。
素人質問ですが、ご助言いただけたら幸いです。
TYX says:
管理人様
ありがとうございます。
大量取得しようとして取得制限でつまずいていたところ、このドキュメントに行きつきました。
やりたかったことまで行けそうです!
tankun says:
管理人様
名前とツイートを同時検索するにはどうしたらよいのでしょうか?
michiam says:
管理人様
はじめまして。わかりやすい記事ありがとうございます。
該当ユーザーのツイート(おそらく1100件)をTwitter開始日から全て取得したいのですが、開始日から2ヶ月半くらいがなぜか取得できません。
ユーザーが絵文字やハッシュタグを多用しているからなのでしょうか?よろしくお願いします。
michiam says:
上記追記です。
2018-10-13〜2020-11-30までのツイートは取れるのですが、それ以前2ヶ月半のツイートが取得できない、と言う意味です。
Twitter API NIGATE says:
管理人様
はじめまして。
大学の研究で、ツイートを利用したいと考えていたところ、この記事にたどり着きました。
本当にわかりやすく、とても助かりました。この記事のおかげで、一週間のツイートを取得することができました。ありがたく存じます。
ここで質問なのですが、自分は一週間以上前のツイートを取得するために普通のkeyだけではなく、(公式の?)keyと、Project申請まで行い、それに対応するAccess Tokenなど4つのkeyを取得したのですが、これを差し替えるだけでは一週間以上前のツイートを取得することができません。
specifyUrlAndParamsメソッド下のurl を'https://api.twitter.com/1.1/search/tweets.json' から 'https://api.twitter.com/1.1/tweets/search/fullarchive/dev/counts.json'に差し替えたのですが、API403エラーが出てしまいます。
他にどこを直すべきでしょうか。ご指摘いただけると、幸いです。知識不足で申し訳ありません。宜しくお願い致します。
Twitter API NIGATE says:
解決しました。ご迷惑をおかけしました。
匿名 says:
管理人様
2021年4月25日現在、上記コードをColaboratory上で実行したところ、ほぼ完璧に動作しています。
しかし、totalを3000件やそれ以上に設定しても、およそ2400~2700件でスクレイピングが停止してしまいます。
何が原因だと考えれられるでしょうか?
匿名 says:
管理人様
上記のコードを元に、日時の範囲を指定してスクレイピングするにはどうすれば良いでしょうか?